

Overview
Introduction
VSAT systems generally connect a large number of geographically dispersed sites to a central location. one of my customers offers VSAT service to different types of business including banking, telecomm. During technical sessions we have had with my customer we witnessed the following challenges in terms QoS:
-
Real-Time service (voice, video) do not fit very well to VSAT data infrastructure very well and results in bad customer experience in both Data Loss and Data Delay quality metrics of these services.
-
VSAT specific bandwidth sharing methods (Multiple Access methods like TDMA, DAMA and etc.) and general QoS optimization on end-point devices (BOD from SATPath Company) conflict with most of QoS devices exist on market since these QoS devices in the market are targeted for more common type of networks.
-
Expensive-to-implement nature of VSAT link relays made some big differences in to a typical form of QoS network users got accustomed to. DAMA allows maximum link utilization based on the bandwidth a site demands resulting poor QoS of most services and increasing network fluctuations which compensates for a reasonable good TCO to restricted-budget customers.
-
Long distance between Access Satellites in geosynchronous orbit and VSAT terminal on earth result in long RTTs in network. Since most QoS techniques are centered around the presence or absence of ACK packet of outgoing TCP packets. Meanwhile RTT around 600ms is common and even ideal in the VSAT environments. It’s almost impossible to determine whether the ACK packet is on the way back or it’s lost.
-
Expensive nature VSAT links persuade customers to have more tendencies toward employing compression-oriented protocols which make it difficult to guaranty any type of QoS to these services and link maximum utilization. The uncertainty of bandwidth consumption on a compressed voice connection over a packet-based network results in more fluctuation and unintentionally dropping quality-critic packets like voice packets. It’s important that any type of QoS in this type of environments must offer the best QoS possible and best link utilization for any type traffic (so-called bulk data) at the same time.
Test Environment
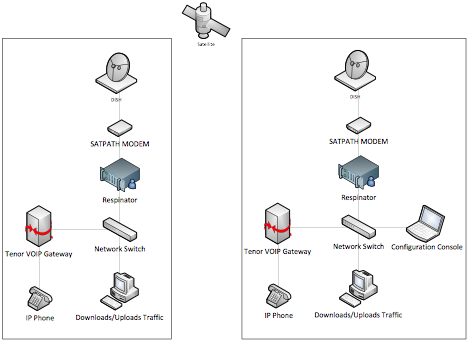
The test environment consisted of two different networks in the same building of my customer. Two networks are connected to each other using a DAMA/Mesh VSAT link and they use SatPath products as modem. Our Product-In-Test sits exactly between the network switch of each one of these networks and the modem. There’s exactly one PC on each one of networks that constantly download/upload files using FileZilla ftp protocol to push the network into congestion. On both networks my customer had employed voice gateways from Tenor Company which are configured to get connected to other voice gateways using H.323 protocol family. On each tests we call one IP phones and listen through from the other IP phone and check the voice quality both in terms of voice lost and voice lags respectively.
The important situation to note is both VSAT end-points are set to use 64Kb bandwidths. Normally H.323 consumes 32Kb in its peak bandwidth usage and 2Kb in its lowest bandwidth usage.
My Attempts
During three technical sessions with have had with my customer we tried several solutions keeping in mind the following practices:
1. The solution must be as simple enough to solve the customer problem, over-perfect solutions not only increase maintenance and support costs but also we might miss the goal in the end. The best approach is to start with simple solutions and increase complexity to project on demand and that’s where the complexity pays off for itself in terms of value and customer satisfaction .
2. Concentrate on customer concerns.
3. Quality matters
4. Customer needs change always.
Session 1: (Warm-up): Experimenting with PRIQ
PRIQ is a queue discipline from AltQ family which prioritizes traffic over other type of traffic. Although the solution came very promising at first glance we came to the conclusion that:
1. PRIQ prioritizes traffic in terms of dequeing the prioritized packets and when it comes to congestion it has no idea which type of traffic to drop to avoid congestion.
2. PRIQ is more suitable when the prioritized traffic relative to whole bandwidth is at small ratio like an SSH traffic over 2Mb traffic.
3. Traffic acceleration and traffic shaping techniques are entirely useless when there’s reasonable amount of congestion in the link.
4. Even when you employ simple PRIQ traffic acceleration methods in uncongested networks you can only accelerate outgoing traffic not incoming traffic, considering we have a long RTT between two endpoints you will need one acceleration device in each end-points at least.
Session 2: Experimenting with HFSC
Apparently HFSC lacks good borrowing mechanism in our scenario and we ended up utilizing roughly half of bandwidth for bulk data. I believe more investigation is needed on HFSC as it is poorly documented in all UNIX man pages and over the internet.
Session 3: Experimenting with CBQ
CBQ had three main characteristics which made the best experiment results we ever had in our scenarios.
1. Borrowing
2. Prioritizing
3. Shaping (the bulk traffic)
Using CBQ we almost reached 90% of voice quality relative to ideal situation (when no bulk traffic exists along voice traffic) in terms of Packet Loss (voice lost) and Packet Delays (voice lags) and getting most of all available bandwidth when no voice data crosses over the link. Next we are going to explain the reasons why we cannot currently approach 100% voice quality.
Late Bulk Traffic Adaptation to Fluctuated Critical Services Phenomena
Unlike uncompressed voice protocols, compressed voice protocols like G.XXX of H.323 protocol family usually use compression in terms of both lossy data compression and lossless compression for their multimedia services. One problem with lossy data compression algorithms is that they are too reliant on acoustic characteristics of the data crossing the wire, some of voice parts and frequencies might easily be eliminated off voice packets without any deceiving affects (e.g. the frequencies that overlap each other). On the other hand lossless compression algorithms depend on abnormality that a voice packet adheres (the more abnormal the packet data is the less it gets compressed). Silence in phone conversations are considered the less abnormal data a carrier can carry so these packets get compressed the most, in comparison to other voice packets in a voice session. There are still some environmental noises in silence although.
Though compression of voice packets saves a considerable amount of bandwidth, it also makes these types of services to have a fluctuating traffic so no conventional queue discipline can anticipate the bandwidth they will require in advance even for next few milliseconds . What queue disciplines like CBQ do is to simply make available the unused bandwidth on voice queue to bulk queue too immediately with zero heuristic ahead and once the voice service wants reclaim the borrowed traffic from bulk traffic queue it takes a little while for bulk traffic to get adopted to new bandwidth (the bandwidth without borrow from voice bandwidth), the problem gets even more severe when RTT is too long (in our case VSAT environment) and TCP hosts have no idea whether they lost the packet or the packet is on the way back because of absence of ACK packets. The problem is illustrated in figure 2.
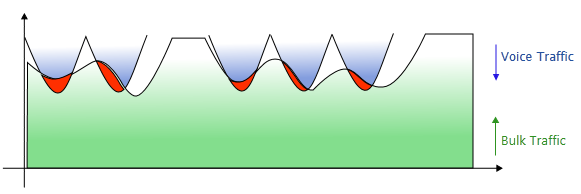
Horizontal axis represents time and the vertical axis represents amount of traffic .The vertical axis for bulk traffic and voice traffic are in opposite direction to highlight clearly the situation where both traffics overlap (the red area) and packet drops happen either by network interfaces or queue disciplines
Proposed Solutions to LBTA-FCS Phenomena
They are two solutions our development team came up with, during a brainstorming session we had recently. Both solutions approach the voice quality to almost 100% of ideal situation (when no bulk traffic exists on link). Solution 1: VIQ , A Modification to CBQ This solution proposed adding a new feature to standard CBQ queue discipline named VIQ. A queue in CBQ hierarchy marked with VIQ flag and provided with a T time parameter is defined as blow. The other queues on hierarchy can borrow unused VIQ queue bandwidth if and only if no packet has crossed the queue in last T milliseconds. altq on em0 cbq bandwidth 2Mb queue { icmp, default } queue icmp bandwidth 500Kb priority 2 cbq(viq 1000) queue default bandwidth 1.5Mb priority 1 cbq(default, borrow) pass out proto ICMP to queue icmp

A simple configuration file for pf.conf using new viq is shown in figure 3, According to definition we can induce that default queue cannot borrow 500Kb bandwidth of icmp queue unless no ICMP packet has crossed the icmp queue for 1000 milliseconds. In real world scenarios one can do the same type of QoS to solve LBTA-FCS problem for any type of real-time services over long RTT networks by just adjusting the right value for T.
Solution: VIQ
We can see VIQ doesn’t borrow the bandwidth from bulk traffic between first two hills in voice traffic whereas the time intervals between first two hills are less than 1000 milliseconds. But as you can see VIQ borrows all voice bandwidth from bulk bandwidth between 2nd and 3ird hills that’s because the time interval between 2nd and 3rd hills are less than 1000 milliseconds.
VIQ seems a promising approach although there’s some disadvantages with it. There’s still some red area in figure 3. The red area (critical point) is due to the fact that it’s impossible for VIQ to predict the 3rd hill even though timeout has been expired and it also takes a little time for bulk traffic to adapt.
Challenges
VIQ must be implemented in Kernel, The modification is very delicate because of criticality of kernel space, every single programming fault can break the whole kernel not only VIQ and network stack. CBQ is a part of AltQ module. AltQ module is not a loadable module so one has to rebuild kernel for each modification to AltQ (I know fastbuild exists on FreeBSD development model but it takes 2 minutes on my PC to fastbuilt FreeBSD kernel) Kernel Debugging is still daunting task to people. We haven’t done that before and it’s probably more time consuming than user-land debugging.
Transition Costs
Despite the disadvantages VIQ it has, it can be considered a general solution to wide-range of real-time services. Even in case of H.323 protocols this solution is less prone to changes that occur during H.323 protocol updates or vendor specific modifications to this protocol. # Research Value It increases development understanding of AltQ and kernel network stack internals. These type insights solidify development team troubleshooting skills when something wrong happens in kernel network stack. This is currently the only opportunity to investigate development of new queue discipline for a real-world need. It also sounds more likely for such solutions to be included in our future products like UTMs and make them available to customers with no fear of how the real-time service is implemented.
Solution 2: H.323 Proxy
All H.323 protocols as defined in their RFC must establish a TCP connection known as Control Connection Control Connection is responsible for all type of control messages two peers need to send each other including establishing a Data Connection, authentication, negotiation for QoS or data connection protocols and ports. Sniffing the whole connection controls brings us valuable information such as
- When Data Connection started exactly.
- What the source and destination IP address of two peers are.
- What the source and destination ports of two peers are.
- When Data Connection stopped exactly.
Using the exact start and stop time of Data Connection we can allocate new queues for the just established Data Connection and keep this queue as long as Data Connection lasts. Having the exact starting time of data connection at hand we even won’t have the tiny red area of congestion introduced in VIQ solution. We can also release the bandwidth allocated for voice queue exactly at the time that peers don’t require their dedicated bandwidth anymore. We believe this solution approaches voice quality up to 100% of ideal situation. Construction We can use the other part of information extracted from control connection to discover the exact source and destination information (IP and port) using these information we can make a zero-configuration device that doesn’t require new configuration in 1. New deployments of device in new environments will become a trivial task for both our support staffs and customers. 2. Network topology changes won’t affect this device, including IP changes of both IP Phones and VOIP gateways. 3. Lowering the cost to support and train customers. 4. Offering more customer-friendly and plug-and-play product.
Risks
H.323 Proxy must not be error-prone to situations where: 1. H.323 Control Connection sends special messages that might be mistaken by negotiation messages. 2. Vendor specific features that take advantages of open parts of H.323 control connection RFC. 3. Administrator specific configurations that affects the behavior of device. There’s no guarantee that device will receive the stop message from peers that TCP connection might be lost or even each one of peer might be defected so it’s a good practice to consider a time-out value for data-connection and release voice bandwidth even if there’s to stop message from control connection. ## Research Value This type of research experiences can be valuable to other type of full connection deep packet inspection; such applications can be IDS and IPS which inspect the connection for all types of viruses, intrusions and etc.