

Overview
This program is an inefficient (in terms of computing and memory complexity) yet simple demonstration to implement k-nearest neighbors unsupervised classification algorithm. This program accepts a CSV file, k nearest neighbors, decision boundary value and K value for cross-validation all as parameter. It calculates accuracy value for different values of decision boundary and k values. The program accepts a coordinate as second and third parameter to classify it either as positive (red) or negative (blue) using the dataset provided. It basically finds the longest distance of in k-neighbor set relative to the given coordinate then it sums up all instances that can be reached from the coordinate, omitting the given coordinate itself.
Testing Method
This example shows two different approaches for validation of classifier, cross-validation and worst-case.
-
Cross-Validation: First all instances are shuffled, then they are split into X folds, which the value of X is already provided as a parameter to the program. The program uses each one of folds as training set and the remaining as test set until it covered all the folds as test set. It also applies one of aggregation functions to summarize results. Different type of aggregation functions implemented (i.e. average, maximum, minimum) to choose (hard-coded). In case of cross-validation average aggregation function has been applied.
-
Worst-Case: In case of worst case the training set is the outer set of 800 of instances relative to center and inner 200 instances for the test set. In the case of worst-case minimum aggregation function has been applied.
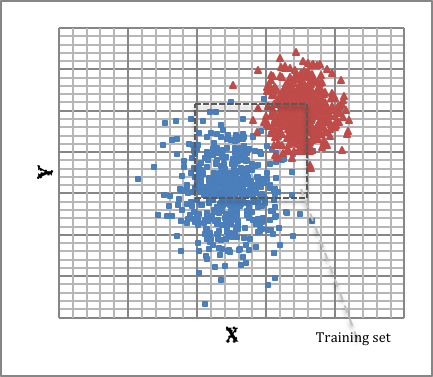
Visualization of dataset in Euclidian space shows distribution of almost all of positive instances in first quadrant and negative instances in third quadrant. There’s some negative instances penetrated into first quadrant but there’s almost no positive case entering into third quadrant.
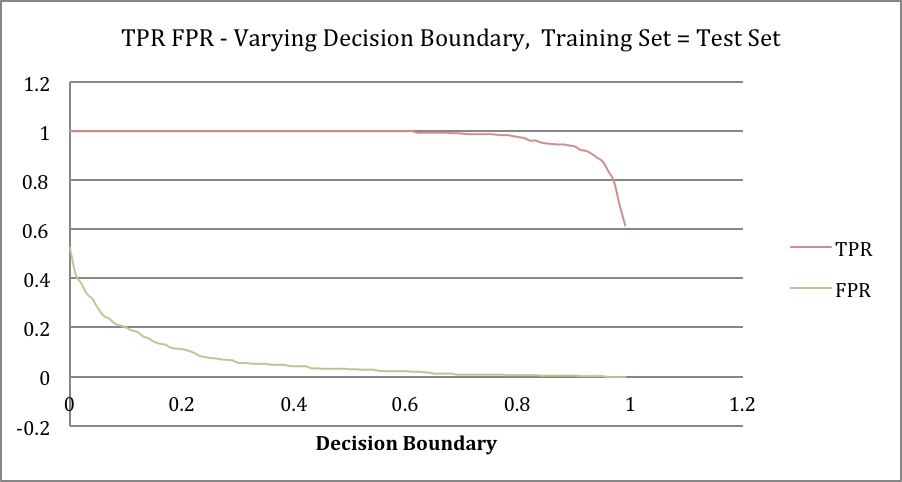
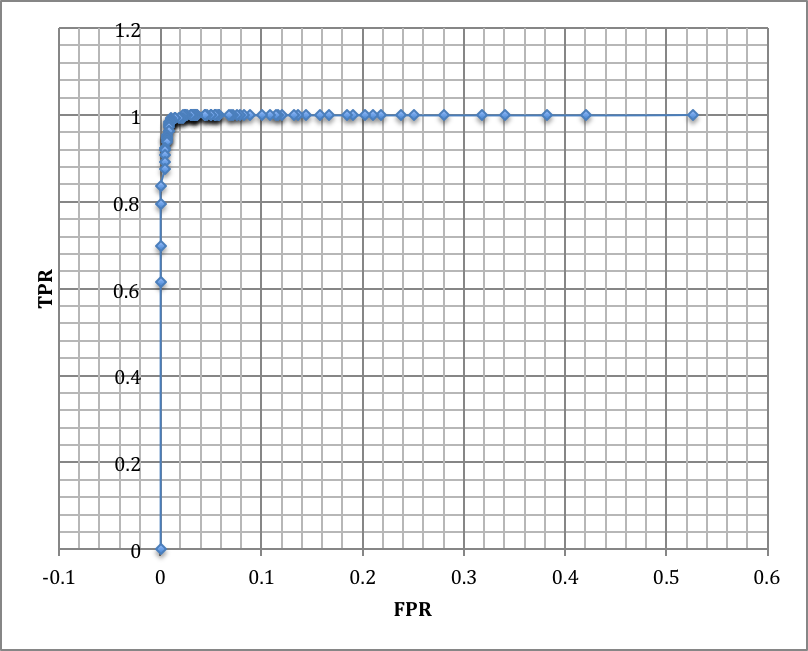
Training set as test set: all instances used for both training set and test set.
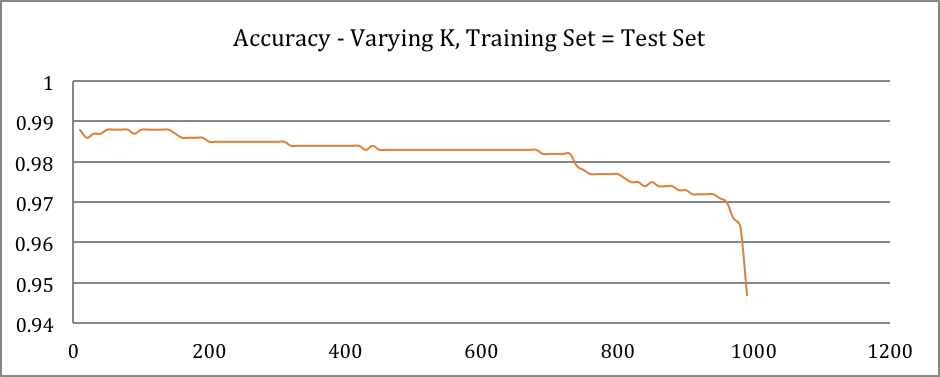
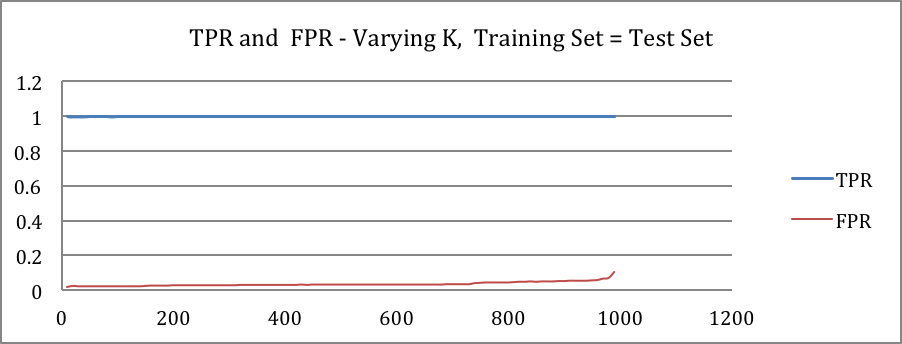
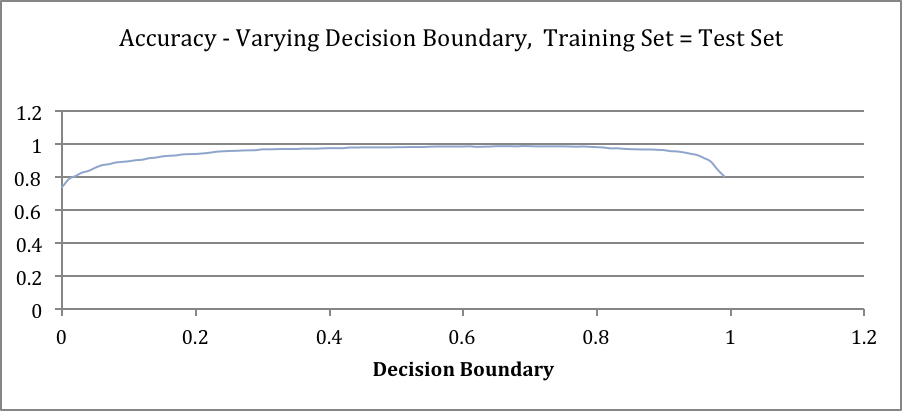
Cross-validation
K folds as test set and K-1 as training set repeatedly covering all data set as test set.
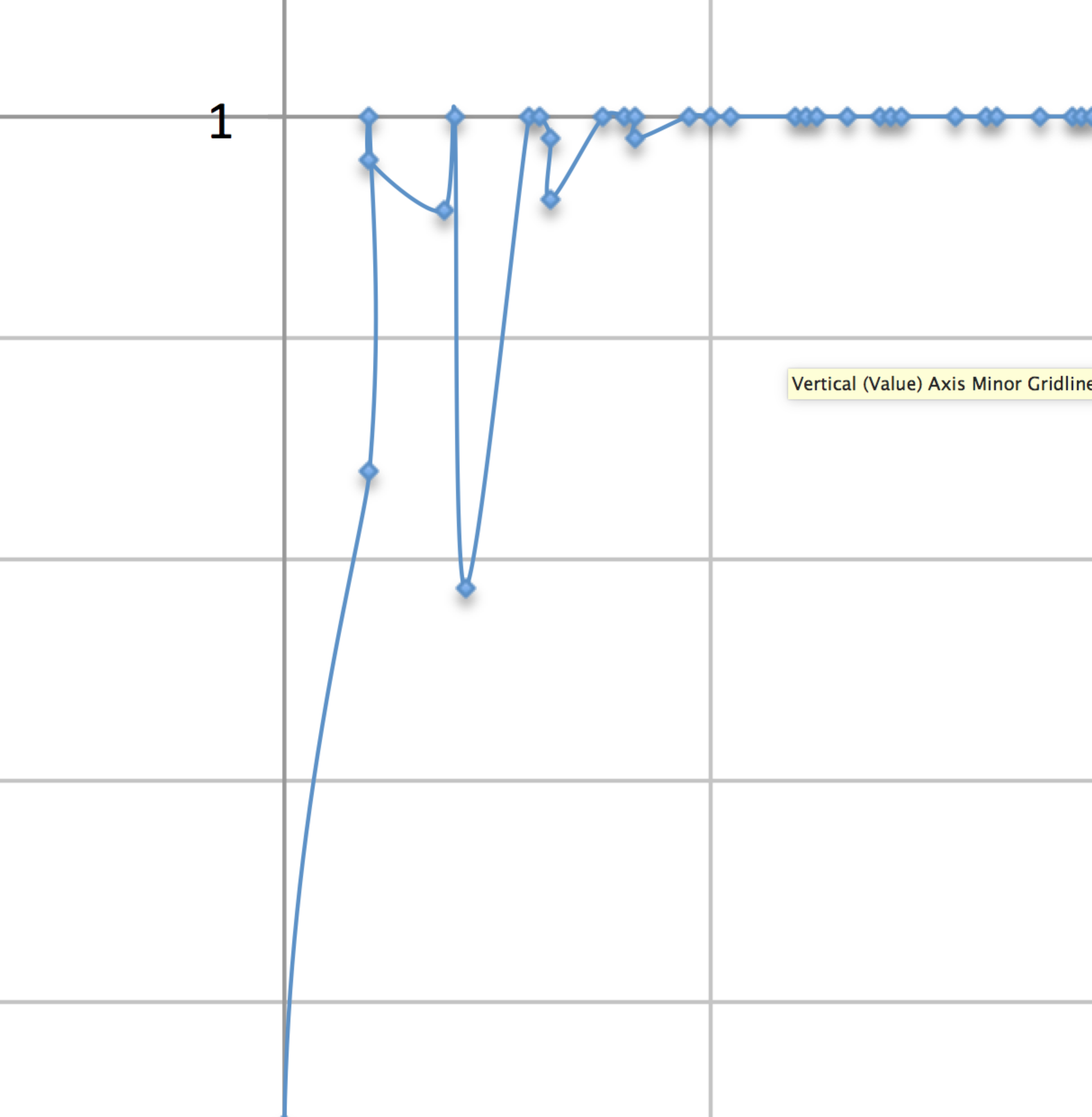
Worst-case
Inner part of dataset used as training set and outer part of dataset used as test set. The purpose is to get worst AUC we can get off the dataset using the same classifier.
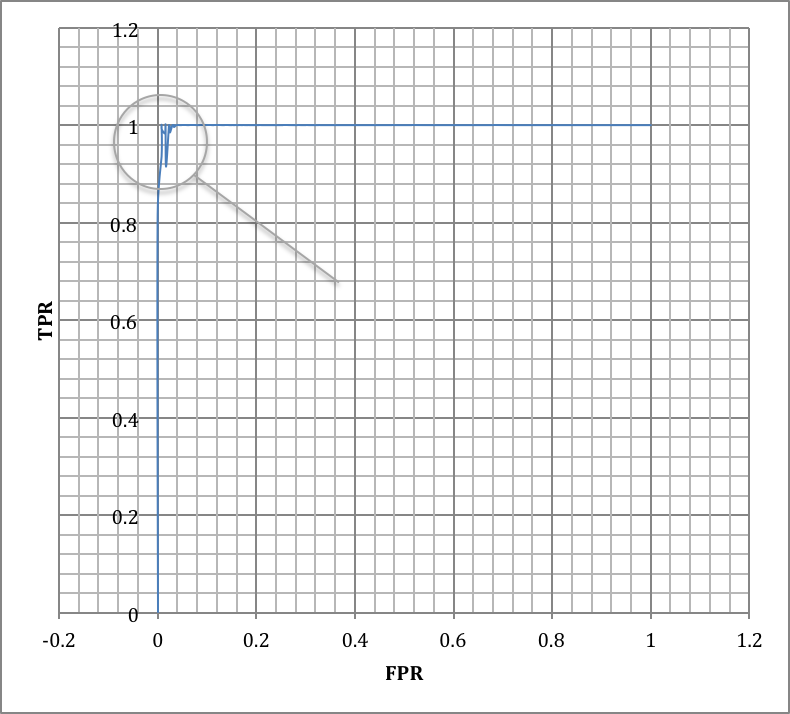
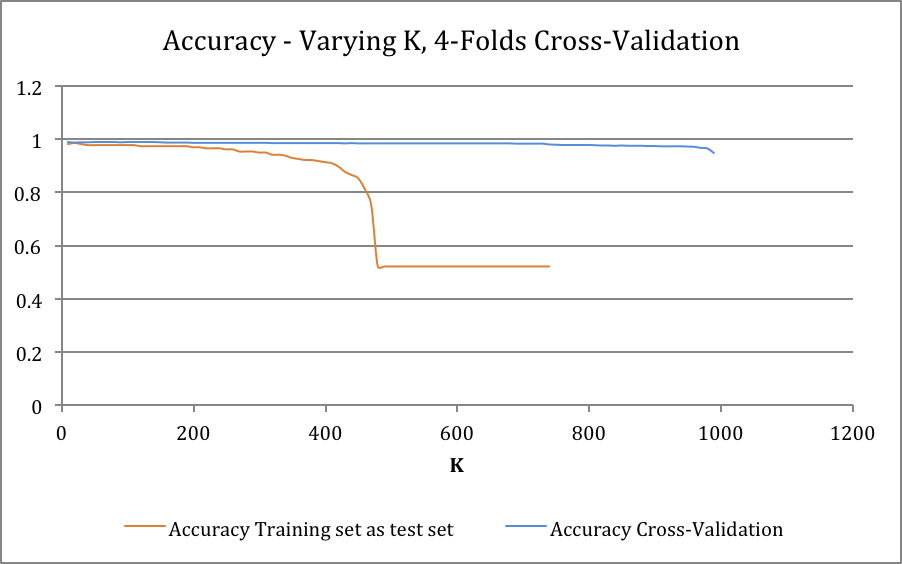
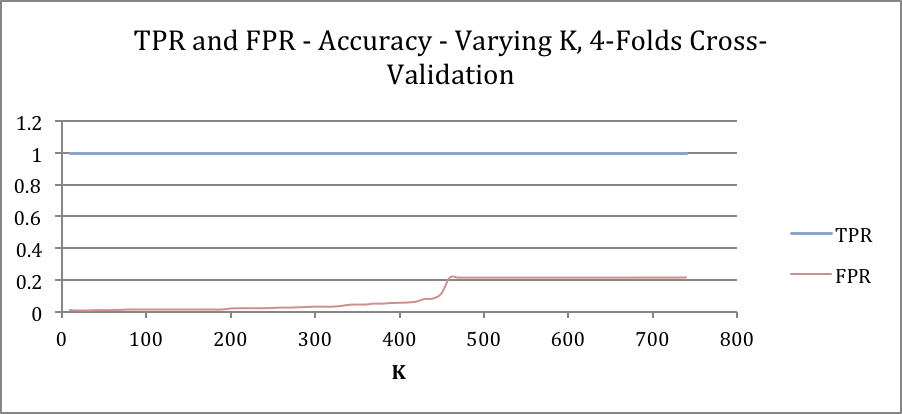
Accuracy curve confirms to the previous results except that they show less complexity (more consistent value with less fluctuation). Remarkably, FPR and TPR show more complexity compared to last results.
Analysis and conclusions comparing all results. Please provide a critical interpretation of what you’re observing in the graphs.
Increasing k for KNN algorithm causes more FPs than TPs. The reason for that is there’s less likely to have a red points in first quadrant to be justified as blue. As red points are relatively adjacent to each other and big k values would not affect classifier substantially. Inversely, some of blue points are scattered into red region and a fairly large value of k can predict them as red as they are all surrounded by red points. Decision boundary is the trade-off of optimism and pessimism. The lower decision boundary increases TPs also increases FPs and vice versa. The curve depicting accuracy over decision boundary value almost forms a Gaussian distribution and implies that a moderate value for decision boundary is most likely the best bet for the given dataset. Dataset contains very few anomalies so ROC shows a near-perfect classifier and AUC is almost maximum. Comparing the fluctuation in results obtained in task 2 and task 3. It may imply that cross-validation alleviates the complexity of accuracy curve and increase of fluctuation FPR and TPR curves and consequently ROC curve increase. But in both cases value curves remain consistent on values for decision boundary near 0 or 1.