

Overview
What’s Azure and why did I use that for project?
The pay-as-you-go plan offers adaptability with no upfront costs and no long-term commitment, which makes cloud computing suitable for research projects and prototyping. Instead of investing in expensive hardware and waiting for them to be ordered and delivered, research teams can provision their hardware and software needs at a glance. It allows other researchers, or even review peers, to validate your experiment results through services or directly with no hassle[1]. It’s also easier to obtain funding for a given project by implementing a prototype of it in cloud with only having a credit card at hand and spending only few dollars especially when you are running out of space in your lab and we are not sure that the given project will be even funded or not.
Specifically speaking, Microsoft Azure differs not much to other cloud providers on the market. Obviously Microsoft specific technologies and products are better supported but it’s not restricted to them. It offers the same very IaaS thing as Amazon EC2 offers which surprisingly enables one to create non-windows VMs on Microsoft data-centers. The same as other cloud infrastructures you can network these VMs together according to the desired architecture.
- Virtual Machines: It’s basically Microsoft Hyper-V technology. Storage: it comes to storage of unstructured data and horizontal scalability they offer Azure Storage that only stores blobs of data.
- Mobile Services: Enables to build and host mobile back-end applications for different mobile platforms using ready to use front-end application templates and libraries. HDInsight: It’s merely deployment of Apache Hadoop on windows clusters but we have the choice .NET programming language in addition of Java.
- Service Bus: Generic naming and communication mechanism for connecting and tracking any type of services and devices together.
- Management Services: Sends alerts via emails if certain measurement reached to a critical point.
- Network Service: Allows to establish different network topologies across virtual machines (virtual network) Technologically specific speaking, Microsoft Azure allows you to run tasks, namely WebJobs, without having to pay for a VM and OS overhead but demand or on planned-schedules. There’s some benefits that come with WebJobs. First of all Azure can recover WebJob in case of failure, e.g. twitter rate limits reached, twitter service shutdowns. It also logs the event. Secondly there’s set monitoring tools to monitor the WebJob activities easily, e.g. CPU usage, network usage. I created a WebJob for “Twitter Network Builder Project” be ran on arbitrary time intervals and on each run it fetches data off twitter and stores them in MongoDB.
Why is it necessary and why you can’t do it without?
I believe it’s more a matter of benefits than necessary. I could still use Mono framework on Mac OSX and use my favorite programming language and library. Regarding profits:
- I can provision new development environment with pre-installed softwares without having to pay for licenses and going through the process of time-consuming software installation and configuration I can keep an eye on my Twitter Network Builder projects from almost everywhere using my smart phone. I can scale-out servers or increase my storage and computation power if later on we decided to work more on this project.
- You and any other students can check or even my share work. We can even hand Complex Networks students with a template VM, a VM that comes with preinstalled libraries, software and even a working base-code of Data Collector if you want to class to be less technical-oriented.
- Microsoft SQL Server Reporting/Analysis/Integration Services are set of tools for BI developers that I’m already familiar with so in case of that tasks such as data cleansing, data visualization, data-mining needed I will be able to do them these tasks quickly and consequently stay focused on research aspect of course. But these software require licenses which we don’t have to pay them on Azure Academic Subscription. The solution
I have prepared three Azure WebJobs to accomplish the following tasks: “CiteTrack Data Collector” which collects tweets using Twitter REST API. The authentication method is based on SingleUser model. It takes care of twitter rate limiting and never lets a duplicated tweet to be added to our collection. It finds the latest TweetId so we can start were we left of in case of failure or crash.
“CiteTrack Data Sweeper” Twitter does a great job of lengthening short urls in tweets. Short url services like bitly.com, goo.gl and tinyurl.com reduce the length of urls to overcome twitter 140 character text limits and also make tweets more human-readable. When you post a shorten url to tweeter, tweeter bots start to resolve the url and check if the url redirect to another url (probably the lengthier one). Fortunatly twitter API provides you with both shortened and lengthened url and you can access the lengthened url by JSON member variable of Tweet.Entities.URLEntities.ExpandedURL. Unfortunately tweeter may record the shortened url once it finds out that the ExpandedURL is too big to be kept in their database systems due to lack of storage (or security vulnarability it may posses?). This WebJob searches through MongoDB documents, stored tweets and expands every Tweet.Entities.URLEntities.ExpandedURL that doesn’t look like a link to arxiv.org
“CiteTrack Extract Metadata” Since 2007 all submissions to arxiv.org retain a consistent schema form is arXiv:YYMM.NNNN, where YY is the year, year MM is the month number, NNNN is a sequence number. Having the identification number in hand one would directly find the abstraction of article by getting to link http://arxiv.org/abs/1408.4311 for example. This WebJob checks the expanded and trimmed url against our regular expression and extracts the arXiv identification and inserts it to our document collection. So we will have an idea that to which paper or arXiv we are referring to exactly.
“CiteTrack Add arXiv Metadata” Once having exact arxiv identification at hand we can obtain quite good amount of metadata regarding the paper using arXiv API like authors name, title, summary, published date and category of paper. It’s a simple REST API and works great.
Sample Document stored in MongoDB, I trimmed unimportant fields in this blog post.
{
// Data Collected by CiteTrack Data Collector WebJob
"_id" : ObjectId("54169502b8d30b1b1897fb55"),
"JsonContent" : null,
"CreatedAt" : ISODate("2014-09-09T07:08:47.000Z"),
"StatusID" : NumberLong(509236962994454528),
"Text" : "Although it sadly didn't get into NIPS2014, my paper Generalized Mixability via Convex Duality is up on arXiv http://t.co/6GGOpW9TZM",
"User" : {
"UserID" : NumberLong(0),
"UserIDResponse" : "2671503234",
"ScreenNameResponse" : "mendibot",
"Name" : "mendibot"
},
"Entities" : {
"UserMentionEntities" : [],
"UrlEntities" : [
{
"Start" : 110,
"End" : 132,
"Url" : "http://t.co/6GGOpW9TZM",
"DisplayUrl" : "bit.ly/1s8s9n5",
"ExpandedUrl" : "http://arxiv.org/abs/1406.6130"
}
]
},
"RetweetedStatus" : {
"RetweetCount" : 0
}
// ArxivId extracted by CiteTrack CiteTrack Data Sweeper
"ArxivId" : "1406.6130",
// Arxiv Metadata obtained by CiteTrack Add arXiv Metadata through arXiv REST API
"ArxivMetadata" : {
"id" : "http://arxiv.org/abs/1406.6130v1",
"updated" : "2014-06-24T03:31:16Z",
"published" : "2014-06-24T03:31:16Z",
"title" : "Generalized Mixability via Entropic Duality",
"summary" : " Mixability is a property of a loss which characterizes when fast convergence\nis possible in the game of prediction with expert advice. We show that a key\nproperty of mixability generalizes, and the exp and log operations present in\nthe usual theory are not as special as one might have thought. In doing this we\nintroduce a more general notion of $\\Phi$-mixability where $\\Phi$ is a general\nentropy (\\ie, any convex function on probabilities). We show how a property\nshared by the convex dual of any such entropy yields a natural algorithm (the\nminimizer of a regret bound) which, analogous to the classical aggregating\nalgorithm, is guaranteed a constant regret when used with $\\Phi$-mixable\nlosses. We characterize precisely which $\\Phi$ have $\\Phi$-mixable losses and\nput forward a number of conjectures about the optimality and relationships\nbetween different choices of entropy.\n",
"author" : [
{
"name" : "Mark D. Reid"
},
{
"name" : "Rafael M. Frongillo"
},
{
"name" : "Robert C. Williamson"
},
{
"name" : "Nishant Mehta"
}
],
"arxiv:comment" : {
"@xmlns:arxiv" : "http://arxiv.org/schemas/atom",
"#text" : "20 pages, 1 figure. Supersedes the work in arXiv:1403.2433 [cs.LG]"
},
"link" : [
{
"@href" : "http://arxiv.org/abs/1406.6130v1",
"@rel" : "alternate",
"@type" : "text/html"
},
{
"@title" : "pdf",
"@href" : "http://arxiv.org/pdf/1406.6130v1",
"@rel" : "related",
"@type" : "application/pdf"
}
],
"arxiv:primary_category" : {
"@xmlns:arxiv" : "http://arxiv.org/schemas/atom",
"@term" : "cs.LG",
"@scheme" : "http://arxiv.org/schemas/atom"
},
"category" : {
"@term" : "cs.LG",
"@scheme" : "http://arxiv.org/schemas/atom"
}
}
}Definition of Edges of Network
We defined relation of two arXiv articles as “two articles are related if they appear by the same user over a specified time window”. In the same context we have a network weighted edges as “The weight of an edge is proportional to number of times its connected pair of nodes(articles) appear on the same tweet by different users”
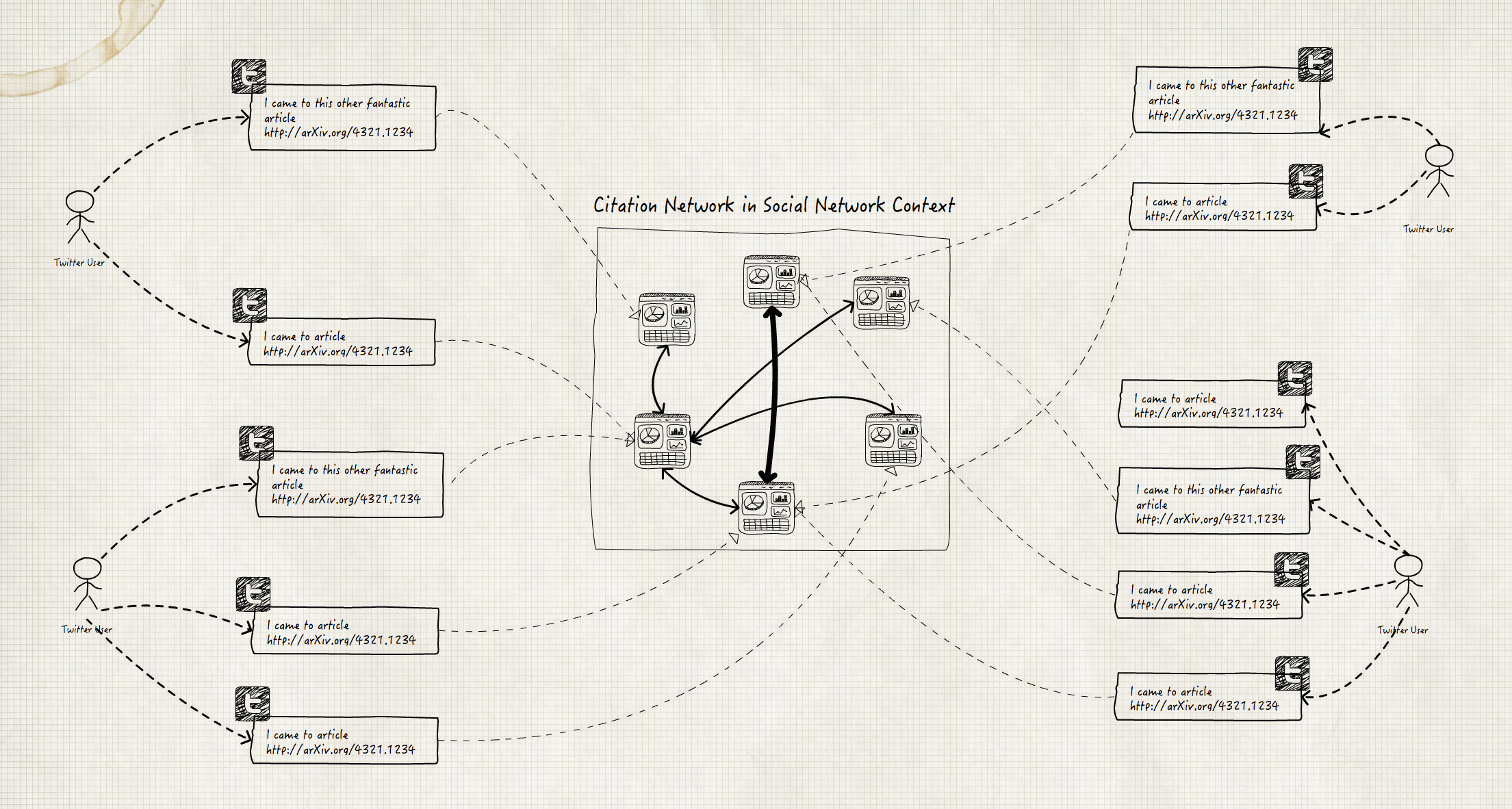
The following MongoDB JavaScript will output all relations between papers taking into consideration that the number of times that pair of papers tweeted by different users and also number of times they retweeted together.
db.Tweets
.aggregate([
{$group: {_id: "$ArxivId", UserIDResponses: { $addToSet: '$User.UserIDResponse' },
RetweetCount: { $sum: '$RetweetCount' }}},
{$project: {UserIDResponses: 1, RetweetCount: {$add: ['$RetweetCount', 1]}}}])
.result
.forEach(function(article) {
article["UserIDResponses"].forEach(function(user) {
db.Tweets.aggregate([
{$match: {'User.UserIDResponse': user, ArxivId: { $exists: 1}}},
{$group: {_id: '$ArxivId', RetweetCount: {$sum: article.RetweetCount}}}])
.result
.forEach(function(userArticles){
if (article['_id'] != userArticles['_id'])
print(article['_id'] + "," + userArticles['_id'] + ","+ userArticles['RetweetCount']);
})
})
})Example output. Thrid column represents the edge weight.
node1,node2,wieight
1409.5171,1409.3394,11
1409.5171,1409.3345,2
1409.5171,1409.3220,45
1409.5171,1409.3381,23
1409.5171,1409.3322,27
1409.5171,1409.1645,1
1409.5171,1409.3799,2
1409.5171,1409.3269,3
1409.5171,1409.3219,6
1409.5171,1409.2132,4
1409.5171,1409.3894,1According to this https://forum.gephi.org/viewtopic.php?t=2299, As duplicate edges are found, the weight of the edge is increased, so I won’t bother with looking up for duplicate edges. There’s some arXiv bots that autmatically post every new paper submission to twitter. They give us no usefull information unless two papers are related. We have to filter them out. So I came up with this new MongoDB JavaScript
// users over posting twitter about arXiv
var bots = db.Tweets.aggregate([
{ $group: { _id: '$User.UserIDResponse' , count: { $sum: 1 }} },
{ $sort: { count: -1} },
{ $limit: 30},
{ $group: { _id: '', Bots: { $addToSet: '$_id' }}}
])
.result[0]
.Bots
print("nodedef>name VARCHAR,title VARCHAR,category VARCHAR");
db.Tweets.aggregate([
{$group: {_id: "$ArxivId", Title: {$first: '$ArxivMetadata.title'}, Category: {$first: "$ArxivMetadata.category.@term"}}} ])
.result
.forEach(function(paper) {
print(
paper._id + ",'" +
(paper.Title || "NA").replace(/(\r\n|\n|\r)/gm,"") + "'," +
(paper.Category|| "NA").toString().replace(/,/g,";")); });
print("edgedef>node1 VARCHAR,node2 VARCHAR, weight INT");
db.Tweets
.aggregate([
{$match: {ArxivId: { $exists: 1}}},
{$match: {'User.UserIDResponse' : {$not: {$in: bots}}}},
{$group: {_id: "$ArxivId", UserIDResponses: { $addToSet: '$User.UserIDResponse'}, RetweetCount: { $sum: '$RetweetCount' }}},
{$project: {UserIDResponses: 1, RetweetCount: {$add: ['$RetweetCount', 1]}}}])
.result
.forEach(function(article) {
article["UserIDResponses"].forEach(function(user) {
db.Tweets.aggregate([
{$match: {ArxivId: { $exists: 1}}},
{$match: {'User.UserIDResponse' : {$not: {$in: bots}}}},
{$match: {'User.UserIDResponse': user}},
{$group: {_id: '$ArxivId', RetweetCount: {$sum: article.RetweetCount}}}])
.result
.forEach(function(userArticles){
if (article['_id'] != userArticles['_id']) {
var weight = Math.pow(userArticles['RetweetCount'] / 1600, 1/4)
print(article['_id'] + "," + userArticles['_id'] + ","+ weight.toPrecision(3));
}
})
})
})I also had to get rid of node with no degree so I used gephi filters to filter out degrees with no node.
After hours of processing I came up with this graph image
